
This incident report describes the tech behind the recent outages in Europe and Brazil which impacted Clash.
Hello folks, Brian "Penrif" Bossé from the Technology department of League of Legends to share details about the technical issues that caused the recent outages in EUW, EUNE, and BR towards the end of February. I'm going to get a little nerdy on y'all here, but if you're curious about the details behind those outages and what we've done to fix them, come with me on a journey with computers and graphs!
Setting the Scene
The first symptom that came to our vigilant Network Operations Center's attention was that the number of League games starting went down drastically.
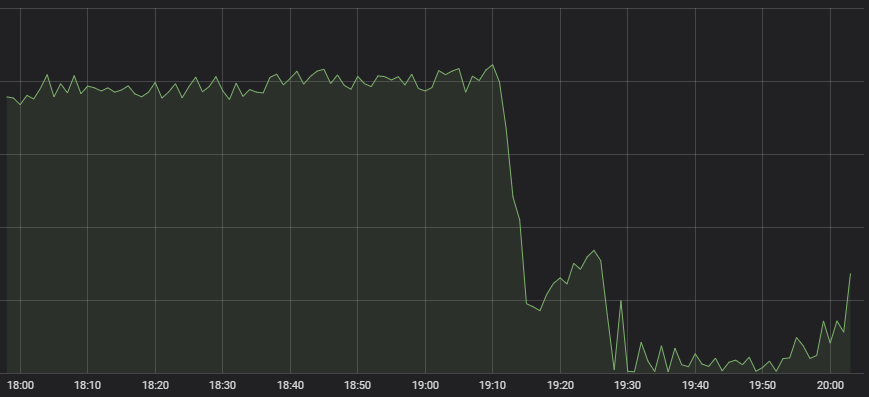
Not typical behavior
There are a lot of systems that go into a successful game creation, from matchmaking to load distribution to the game server itself, and it's not immediately clear from a symptom like this where the breakdown is. When we brought the experts in each of those systems into triage to make that determination, they all indicated that their service's health looked good, but very little traffic was coming in to them. A matchmaker with few people coming in to request a match doesn't have much to do.
So, all of that indicated that we're dealing with a systemic issue in getting player traffic into our backend. Metrics showed us some major problems in that neighborhood:
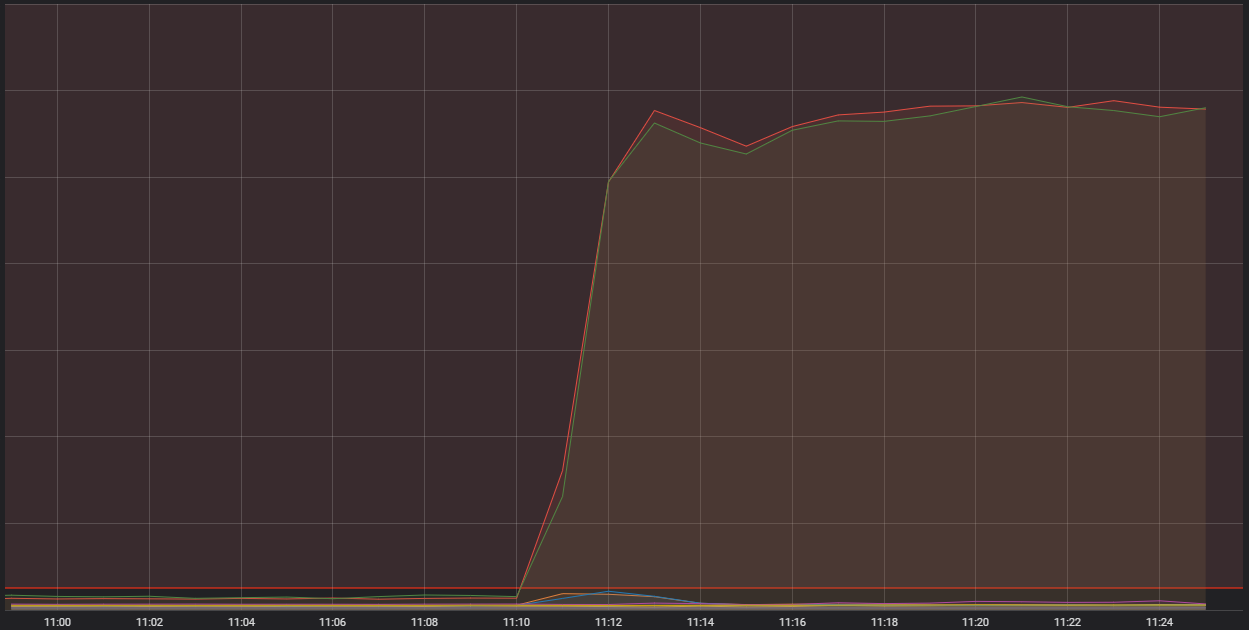
The horizontal red line all the way at the bottom is where sirens go off
What we're looking at here is the number of inbound connections to one of our generic container hosts. Those are highly capable single computers that run a bunch of smaller applications - in shop-talk, containers - that comprise the overall system that runs League. Two of those hosts are getting vastly more connections than is reasonable. To understand why, we need to talk about a particular kind of container, one performing an "edge" function.
Living on the Edge
Edge processes are tasked with taking in traffic from the internet, filtering it, and routing it to the appropriate backend service. They take the garbage pile that is the public internet and leave only nice, clean stream of bytes for everyone else to process in comfort. As you can imagine, edge processes go through a lot of traffic, but really shouldn't regularly see the kind of spike we saw during these events. There are three factors that all lined up to create this situation; I'll give them each a section then pull it all together.
So It Begins
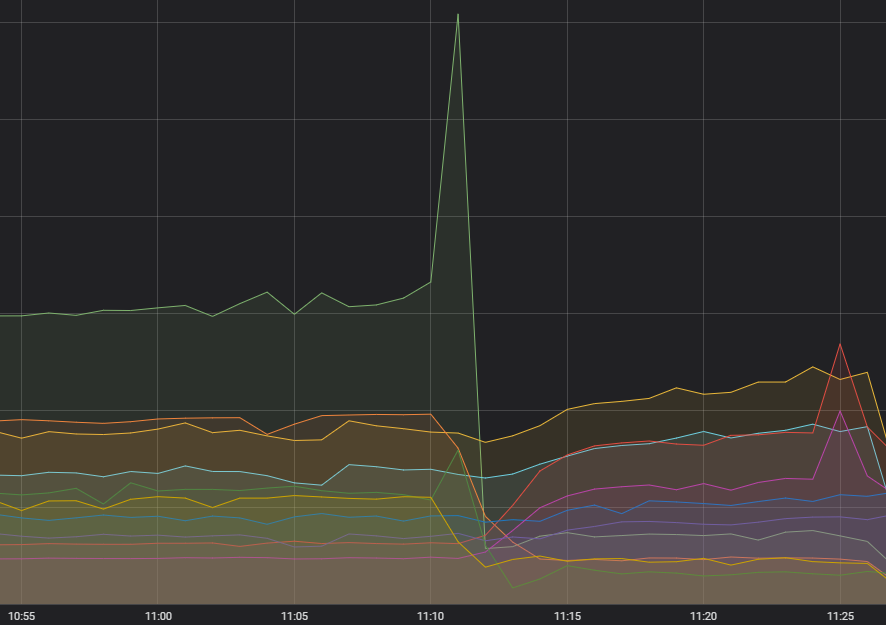
First up, the spark that started the cascade - an unreasonable amount of requests to one service. For a few months we've noticed an increase in the volatility of call frequency targeted towards that service, but it didn't appear to have any impact and all of the upstream systems had been handling it fine. Diagnosing something that wasn't hurting anyone didn't rank as a high priority for active effort, but we kept it in the back of our minds. We've diagnosed it now though; there was an error in how the request was being made which, in certain cases, would cause it to constantly fail - and constantly be retried.
Containers Sprung a Leak
We had a known issue involving an interaction of our container system with the operating system version in use. The problem involved a leak of memory inside the bowels of the operating system, which given enough time to build up, could halt critical system functions. Prior to this event we had never seen that manifest, but we had already executed upgrades on about 60% of Riot's container fleet anyway. Unfortunately, the update to Europe and Latin America's clusters was still in progress.
Luck Matters
And lastly, we got unlucky. We utilize a piece of software to group up the containers into bunches that can fit on a single host computer. It has constraints programmed into it for keeping these network-heavy edge services separate from each other within the same shard's set of containers. However, we couldn't control if edge services from different shards could land on the same computer, so edge services from EUW could end up sitting right next to edge services from EUNE. That multiplication of load onto a single machine was the magnifier that threw the prior two problems into a major incident.
On all of the outages, edge containers from at least three shards were put on to a single host. With a spark of traffic from the malformed requests, amplified by having multiple shards worth of that traffic hitting the same host, then the operating system memory leak pushing that machine into a non-functional state, we experienced a breakdown of the integrity of the shard, and significant outage.
Impact and Resolution
It generally takes significant effort to untangle this kind of problem and find isolated causes. When we needed to make the call on whether to go forward with Clash on top of a potentially unstable cluster, we had suspicions that the container problems were a key part of the picture, but did not yet have a handle on what the traffic was exactly. Even though the issue was not at all caused by Clash, we made the decision to delay a week in order to be sure that the Clash experience would be protected. I sincerely apologize for the disruption these events caused, and want to assure you that we have fixes for every aspect that played into them.

The code causing broken requests to be sent has been corrected, and just in case we have similar problems in the future, we've changed how the retry mechanism works to avoid them from causing large spikes. The container software upgrade has been completed on all of our shards. We have concrete plans for moving the edge services to a balancing system that can accommodate spreading them out cross-shard. Until those plans are executed, we have alerting in place so someone's phone gets turned into a screaming angerbox until the load is manually redistributed.
We feel confident that with all of these different causes behind us, this particular issue will not happen again. That said, we're continually evolving the game and its supporting systems, and situations like this are always a possibility. We’re committed to restoring service as quickly as we can when they do. Thanks for making it to the end here; if this sort of content sparks your curiosity, you can catch more in-depth League technology articles over at our TechBlog. Either way, I'll see you all on the Rift.