
Ten raport z incydentu opisuje kwestie techniczne związane z niedawnymi awariami w Europie i Brazylii, które wywarły wpływ na Clash.
Cześć wszystkim, tu Brian „Penrif” Bossé z Działu technologicznego League of Legends. Chcę się z wami podzielić szczegółami dotyczącymi problemów technicznych skutkujących niedawnymi awariami w EUW, EUNE i BR, do których doszło pod koniec lutego. W tym tekście wyjdzie ze mnie technologiczny nerd, ale jeśli interesują was informacje rzucające więcej światła na wspomniane awarie i na to, jak sobie z nimi poradziliśmy, zapraszam do udziału w przygodzie w świecie pełnym komputerów i wykresów!
Co nieco tła
Pierwszym objawem, który zwrócił uwagę naszego Centrum Operacji Sieciowych, był drastyczny spadek liczby gier League.
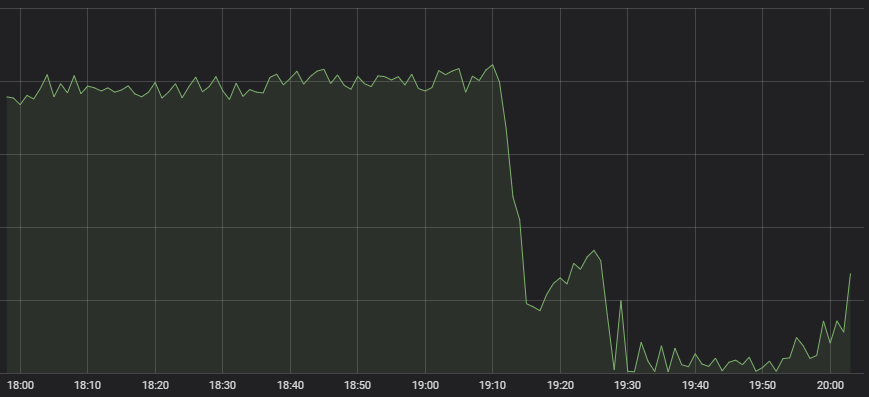
Nietypowe działanie
Na powstanie prawidłowo działającej gry składa się wiele systemów, od dobierania przeciwników, przez rozłożenie obciążenia, aż po serwer gry. I gdy wystąpi jakiś symptom problemu, niekoniecznie od razu wiadomo, w którym miejscu coś poszło źle. Gdy poprosiliśmy ekspertów zajmujących się poszczególnymi systemami o rozpoznanie sytuacji, każdy z nich zauważył, że choć wszystkie usługi funkcjonowały poprawnie, to docierało do nich bardzo niewiele ruchu. System dobierania graczy z małą liczbą osób zgłaszających chęć gry będzie bezczynny.
Dlatego wszystkie znaki na niebie i ziemi świadczyły, że wystąpiła nieprawidłowość systemowa, wskutek której ruch generowany przez graczy do nas nie dochodził. Dostępne dane wskazywały na poważne problemy w tym zakresie:
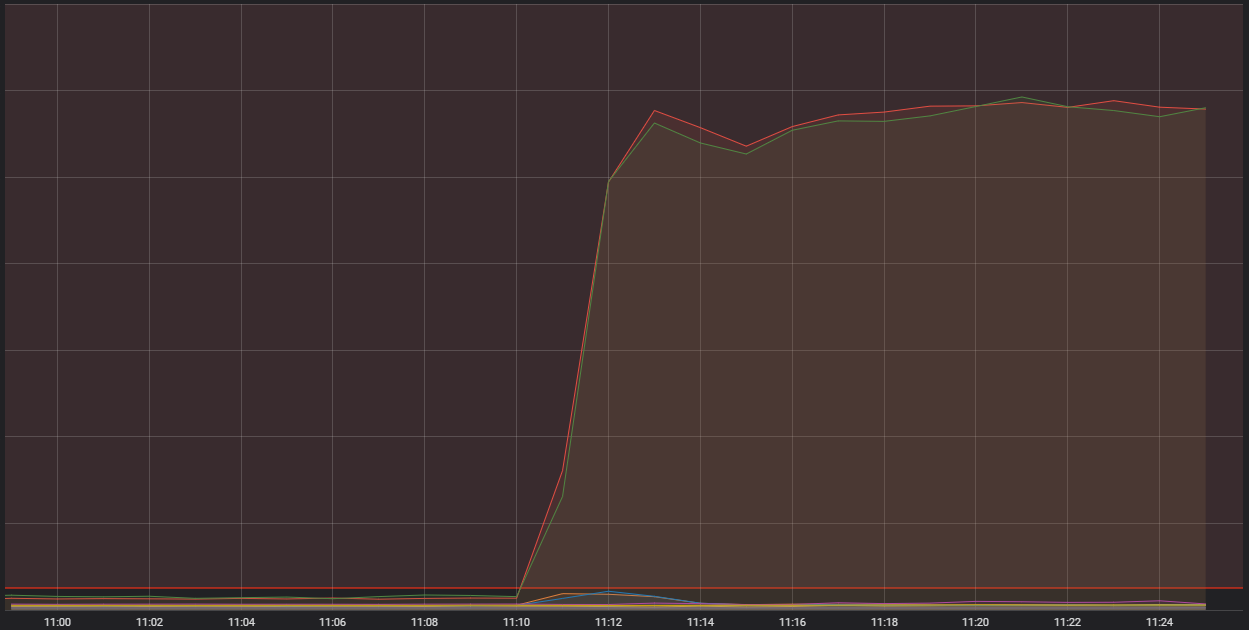
Pozioma linia koloru czerwonego sięgająca dna oznacza, że pora bić na alarm
Widoczny u góry wykres prezentuje liczbę połączeń przychodzących, które docierają do jednego z naszych hostów kontenerowych. To pojedyncze, wysokowydajne komputery — w żargonie technicznym określane jako „kontenery” — obsługujące szereg mniejszych aplikacji. I właśnie na tych maszynach opiera się cały system umożliwiający działanie League. Dwa z tych hostów przyjmują o wiele więcej połączeń niż powinny. Aby zrozumieć przyczynę tego stanu rzeczy, musimy wspomnieć o szczególnym rodzaju kontenera wykonującego funkcję brzegową (ang. „edge”).
Bezbrzeżne ryzyko
Procesy brzegowe mają za zadanie przyjmować ruch przychodzący z Internetu, filtrować go, a następnie przesyłać do właściwej usługi zaplecza. Biorą one „na klatę” chaotyczną masę danych z ogólnodostępnego Internetu, a po jej przesianiu pozostawiają wyłącznie uporządkowany, czysty strumień bajtów, tak aby inni mogli go bez problemu poddać obróbce. Jak możecie się domyślić, procesy brzegowe przekopują się przez mnóstwo sieciowego ruchu, ale mimo wszystko ich przebiegowi nie powinny towarzyszyć tak raptowne skoki obciążenia jak te, które ostatnio wystąpiły. Do zaistniałej sytuacji doszło wskutek wystąpienia trzech czynników. Omówię po kolei każdy z nich, aby potem je podsumować.
Od czegoś trzeba zacząć
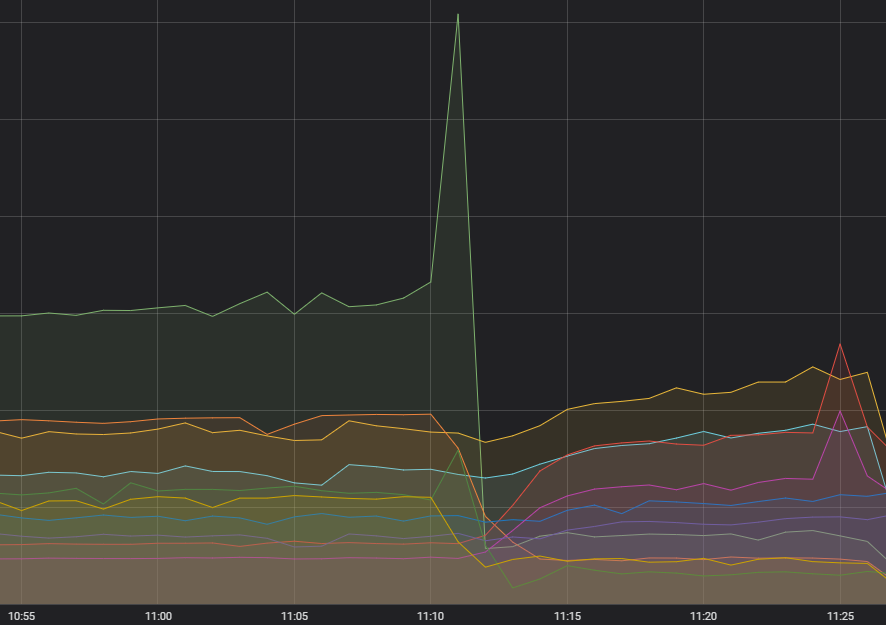
Pożar często powoduje pierwsza iskra, którą w tym przypadku była nadmiernie wysoka liczba żądań wysłanych do jednej usługi. W ciągu kilku ostatnich miesięcy zaobserwowaliśmy zwiększoną nieprzewidywalność zgłoszeń kierowanych do wspomnianej usługi, ale wyglądało na to, że są one nieszkodliwe i że wszystkie systemy nadrzędne dobrze sobie z tym zgłoszeniami radzą. Diagnozowanie nieszkodliwego zjawiska miało względnie niski priorytet, dlatego nie podjęliśmy działań w tym zakresie, choć pamiętaliśmy o jego istnieniu. Teraz jednak zidentyfikowaliśmy ten proces: żądanie było zgłaszane w błędny sposób i w takich przypadkach nigdy nie dochodziło do skutku, tylko było cały czas ponawiane.
Kontenery zaczęły przeciekać
Wystąpił znany problem, w ramach którego dochodziło do interakcji naszego systemu kontenerów z używaną wersją systemu operacyjnego. Doszło między innymi do przecieku pamięci głęboko wewnątrz systemu operacyjnego. Przeciek ten — jeżeli trwał wystarczająco długo — mógł spowodować zatrzymanie najważniejszych funkcji systemowych. Przed tym incydentem nigdy nie zetknęliśmy się z tego typu objawem, ale już wtedy zdążyliśmy ulepszyć około 60% kontenerów Riot. Niestety, aktualizacja grup w Europie i Ameryce Łacińskiej nadal była w toku.
Jak pech to pech
No i ostatnia rzecz: nie mieliśmy szczęścia. Korzystamy z oprogramowania, które grupuje kontenery w segmenty mieszczące się na pojedynczym komputerze-hoście. Zawiera ono zaprogramowane ograniczenia, które mają oddzielać obciążające sieć usługi brzegowe w zestawie kontenerów przynależących do konkretnego odłamka. Nie mieliśmy jednak wpływu na sytuacje, w których usługi brzegowe z odmiennych odłamków mogły trafić na ten sam komputer, w związku z czym usługi brzegowe z EUW mogły zaleźć się tuż obok usług brzegowych z EUNE. Zwielokrotnienie obciążenia pojedynczego komputera okazało się katalizatorem, który zamienił dwa wyżej opisane problemy w poważny incydent.
W przypadku wszystkich awarii doszło do tego, że kontenery brzegowe z co najmniej trzech odłamków zostały umieszczone w tym samym hoście. Ruch pochodzący z nieprawidłowych żądań, spotęgowany przez pochodzący z wielu odłamków ruch trafiający do tego samego hosta, oraz wyciek pamięci w systemie operacyjnym skutkujący „obezwładnieniem” tego komputera — oto czynniki, które doprowadziły do dysfunkcji odłamka i poważnej awarii.
Skutki i rozwiązanie
Rozwiązanie takiego problemu i zidentyfikowanie poszczególnych przyczyn jest pracochłonnym wysiłkiem. Gdy musieliśmy podjąć decyzję, czy wystartować z Clashem z potencjalnie niestabilną grupą w tle, podejrzewaliśmy, że problemy z kontenerami stanowiły istotę problemu. Nie mieliśmy jednak dokładnej wiedzy na temat aktualnego natężenia ruchu. I mimo że Clash nie miał żadnego związku z awarią, postanowiliśmy opóźnić to wydarzenie o tydzień, aby upewnić się, że jego przebieg będzie niezakłócony. Z całego serca przepraszam za niedogodności wynikłe z tych problemów. Pragnę was jednocześnie zapewnić, że jesteśmy w stanie usunąć każdą z przyczyn, które doprowadziły do ich powstania.

Kod powodujący wysyłanie wadliwych żądań został poprawiony. Chcąc się zabezpieczyć przed podobnymi problemami w przyszłości, zmieniliśmy sposób działania mechanizmu ponawiania żądań tak, aby nie dochodziło do ich kumulacji. Zaktualizowaliśmy oprogramowanie kontenerowe obsługujące wszystkie nasze odłamki. Mamy konkretne plany przeniesienia usług brzegowych do zapewniającego równowagę systemu, który będzie w stanie równomiernie je rozdzielać w ramach odłamka. Zanim jednak tak się stanie, będziemy korzystać z już wdrożonej procedury alarmowej, zgodnie z którą dyżurująca pod telefonem osoba nie zazna spokoju, dopóki nie zlikwiduje powstałego obciążenia ręcznie.
Teraz, gdy już uporaliśmy się z rozmaitymi przyczynami tego problemu, jesteśmy pewni, że nie wystąpi on ponownie. Mimo wszystko jednak cały czas pracujemy nad grą i systemami jej wspierania, więc tego typu sytuacje pozostają prawdopodobne. Niezmiennie zależy nam na jak najszybszym przywróceniu niedziałających usług. Dziękuję wam, że dobrnęliście ze mną do końca. Jeżeli tego typu treści was ciekawią, możecie zapoznać się artykułami szerzej omawiającymi technologię League publikowanymi na naszym blogu technicznym. Tak czy owak widzimy się na Summoner’s Rift.